Drupal 10: Fully local, open source Drupal AI setup, part 1: Search API
| Changelog | |
|---|---|
| Jul 29, 2025 | Updated for the latest versions of the Drupal AI modules. |
A recent interaction on the Drupal community’s Slack prompted me to describe the work I’ve been doing to create a fully local, open source setup for Drupal AI tools. My use case is to provide relevant search results based on natural language (English) queries. There are deployment scenarios, such as government projects, where the full system needs to be deployed in the home country and to avoid communicating with API services located elsewhere - this is the scenario that interests me here. Since I received positive feedback on my system description, I thought I’d clean it up and share it here. Hope it helps someone!
Theory of operation
The general idea of using Search API with natural language queries is to create vector embeddings of the relevant content, which are then matched against the embedding of the incoming user query. Vector embeddings are computed by an LLM (Large Language Model, in case you just landed on our planet) that is served by a local instance of Ollama running on my CPU-only laptop. At this time, I am using the LLM mxbai-embed-large to generate the embedding vectors. These vectors are stored in the same database as Drupal - I always use PostgreSQL and its pgvector extension turns it into a perfectly acceptable vector database. The pretty amazing Drupal AI ecosystem supports these tools out of the box, so there’s almost no coding involved in this setup. Drupal AI even provides a Search API connector that is able to perform vector indexing within the familiar Drupal search infrastructure.

I’ll be illustrating this setup with content from WorkBC.ca, a large Drupal site for the Ministry of Post-Secondary Education and Future Skills, British Columbia, that my team and I have been building and maintaining for the past 2+ years. The content describes the 500+ official careers that are identified by the Federal Government of Canada as representing the Canadian workforce.
Docker setup
I always start with Docker Compose. I use the excellent Wodby Drupal stack as a starting point - it includes all needed services and has intelligent defaults. In my case, I want to add ollama to the services, as well as inject the pgvector extension into Postgres - here are the relevant bits:
# docker-compose.yml
services:
ollama:
image: ollama/ollama:${OLLAMA_TAG}
ports:
- "11434:11434"
volumes:
- /usr/share/ollama/.ollama:/root/.ollama # To store models on my local host
postgres:
build:
context: .
dockerfile: pgvector.Dockerfile
args:
POSTGRES_TAG: ${POSTGRES_TAG}
PGVECTOR_TAG: ${PGVECTOR_TAG}
# pgvector.Dockerfile
ARG POSTGRES_TAG
FROM wodby/postgres:${POSTGRES_TAG} AS pgvector-builder
ARG PGVECTOR_TAG
RUN apk add git
RUN apk add build-base
RUN apk add clang
RUN apk add llvm-dev
WORKDIR /home
RUN git clone --branch v${PGVECTOR_TAG} https://github.com/pgvector/pgvector.git
WORKDIR /home/pgvector
RUN make
RUN make install
FROM wodby/postgres:${POSTGRES_TAG}
COPY --from=pgvector-builder /usr/local/lib/postgresql/bitcode/vector.index.bc /usr/local/lib/postgresql/bitcode/vector.index.bc
COPY --from=pgvector-builder /usr/local/lib/postgresql/vector.so /usr/local/lib/postgresql/vector.so
COPY --from=pgvector-builder /usr/local/share/postgresql/extension /usr/local/share/postgresql/extension
We are now ready to download the embedding model:
docker-compose run ollama
docker-compose exec ollama ollama pull mxbai-embed-large:latest # in a different console
Drupal modules setup
Here is the relevant configuration in my composer.json file:
{
"require": {
"drupal/ai": "^1.2@alpha",
"drupal/ai_provider_ollama": "^1.1@beta",
"drupal/ai_vdb_provider_postgres": "^1.0@alpha",
}
}
and the enabled modules:
wodby@php.container:/var/www/html $ drush pml | grep AI
AI AI Core (ai) Enabled 1.2.0-alpha1
AI Providers DropAI Provider (dropai_provider) Disabled 1.2.0-alpha1
AI AI API Explorer (ai_api_explorer) Enabled 1.2.0-alpha1
AI Tools AI Assistant API (ai_assistant_api) Disabled 1.2.0-alpha1
AI AI Automators (ai_automators) Disabled 1.2.0-alpha1
AI Tools AI Chatbot (ai_chatbot) Disabled 1.2.0-alpha1
AI AI CKEditor integration (ai_ckeditor) Disabled 1.2.0-alpha1
AI AI Content Suggestions (ai_content_suggestions) Disabled 1.2.0-alpha1
AI AI ECA integration (ai_eca) Disabled 1.2.0-alpha1
AI AI External Moderation (Deprecated) (ai_external_moderation) Disabled 1.2.0-alpha1
AI AI Logging (ai_logging) Disabled 1.2.0-alpha1
AI (Experimental) AI Search (ai_search) Enabled 1.2.0-alpha1
AI AI Translate (ai_translate) Disabled 1.2.0-alpha1
AI AI Validations (ai_validations) Disabled 1.2.0-alpha1
AI Providers Ollama Provider (ai_provider_ollama) Enabled 1.1.0-beta2
AI Vector Database Providers (Experimental) Postgres VDB Provider (ai_vdb_provider_postgres) Enabled 1.0.0-alpha2
Drupal AI setup
With the infrastructure ready, it’s now time to configure the Drupal AI components and wire them together. I’ll be using the Admin UI with URIs and screenshots to better illustrate the setup.
/admin/config/ai/providers/ollama
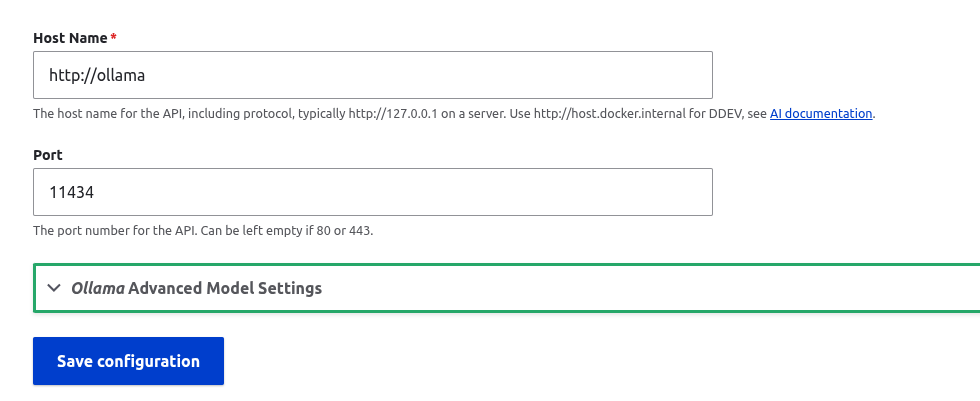
/admin/config/ai/settings
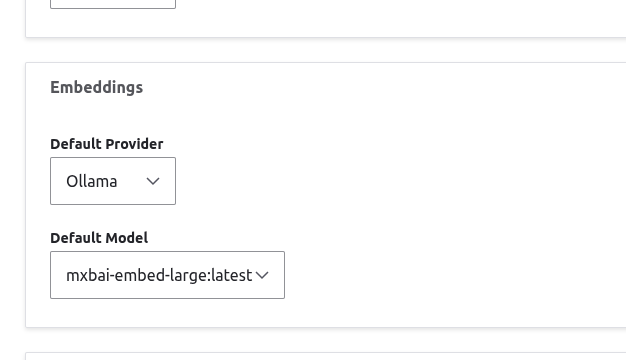
/admin/config/ai/vdb_providers/postgres
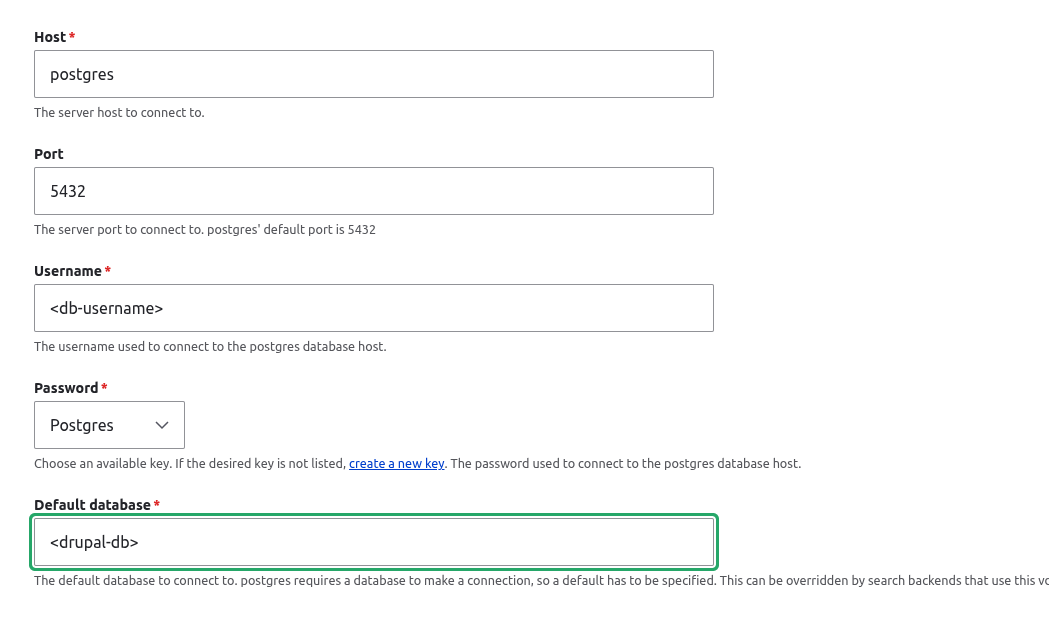
/admin/config/search/search-api
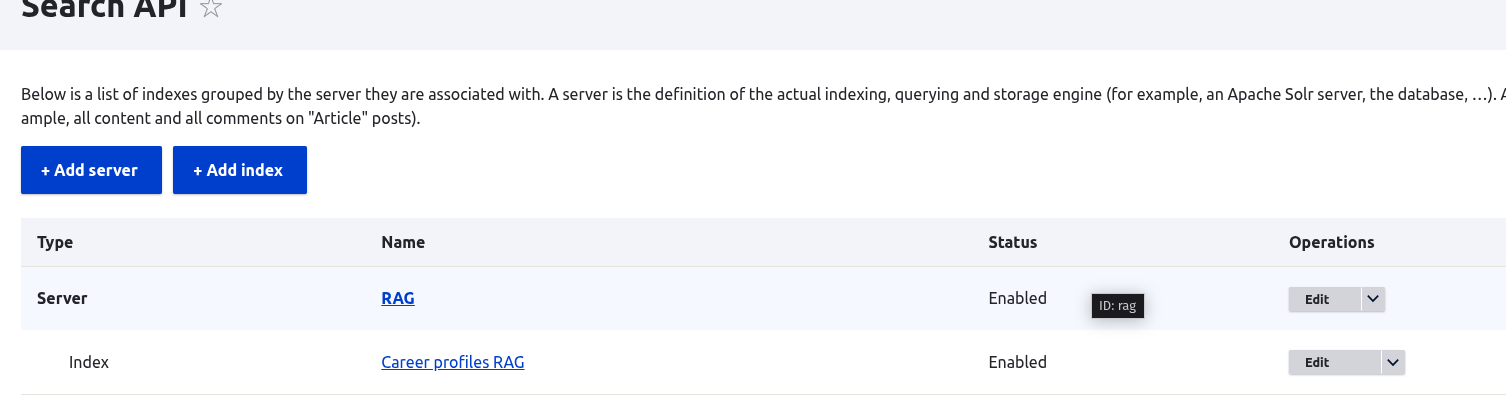
/admin/config/search/search-api/server/rag/edit
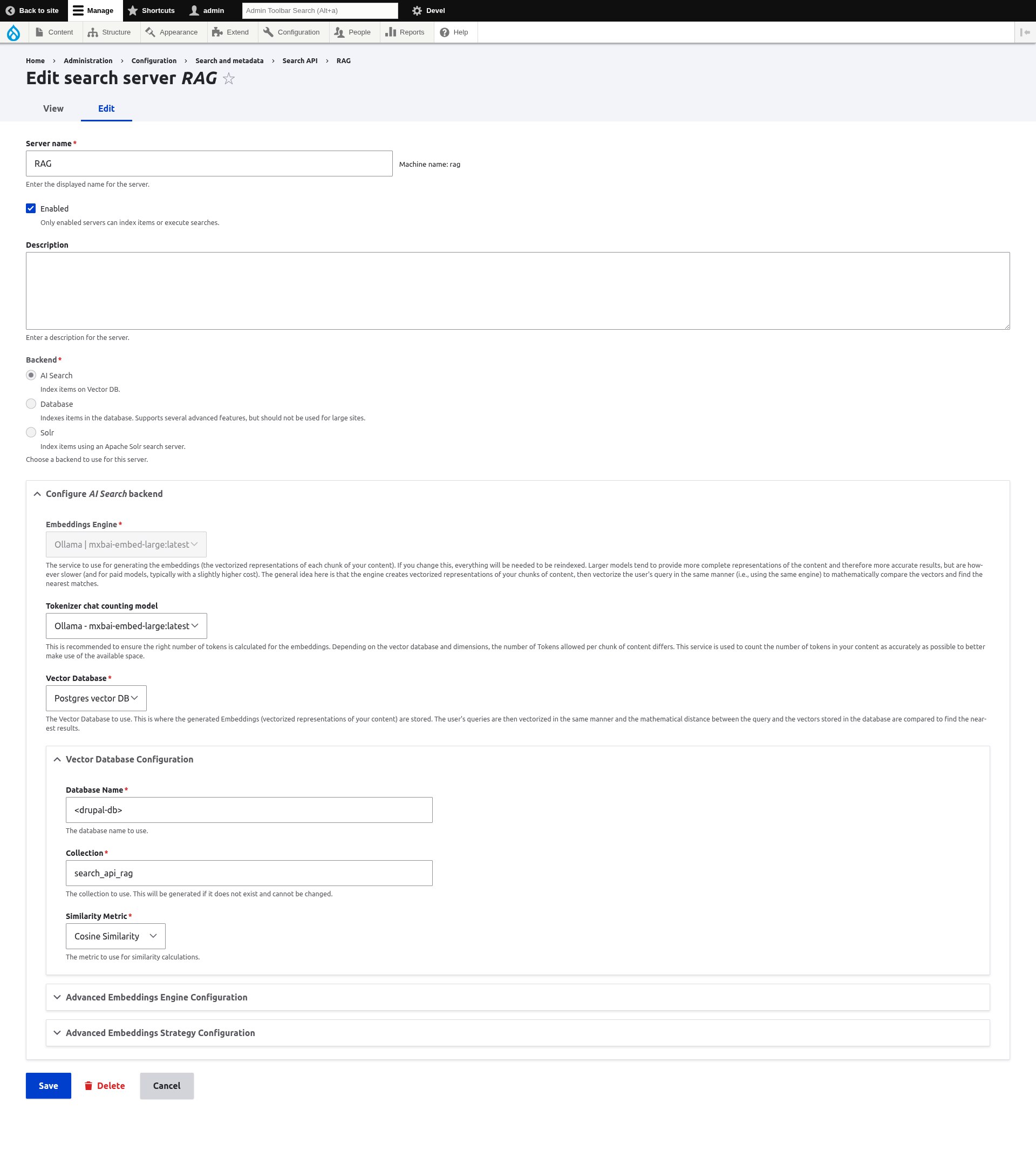
Note the Vector Database Configuration > Collection setting search_api_rag which is the name of a database table created to hold the vector embeddings.
/admin/config/search/search-api/index/career_profiles_rag/edit
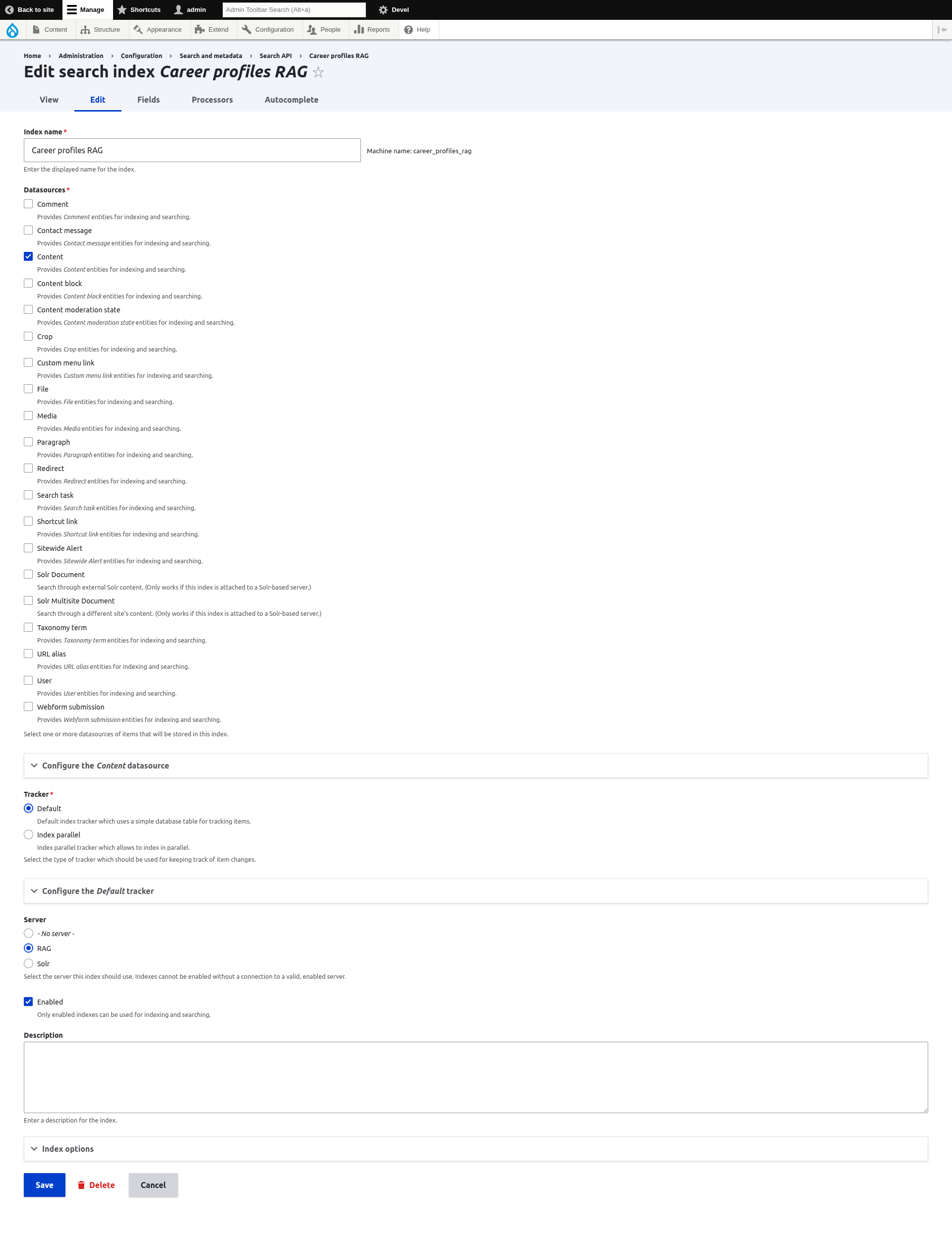
/admin/config/search/search-api/index/career_profiles_rag/fields
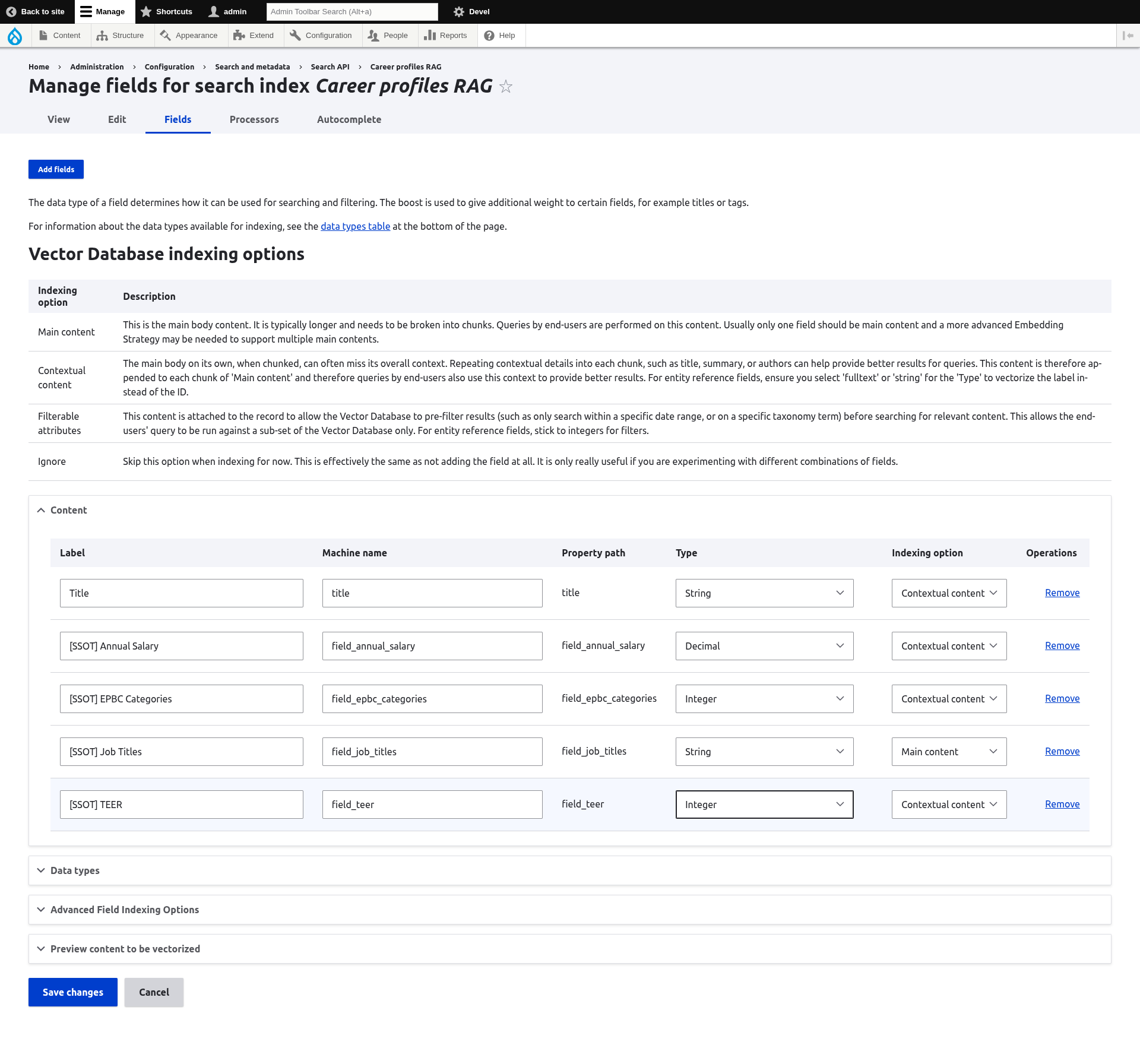
The tricky bit here is understanding the Indexing option setting - namely, the difference between Contextual content and Main content for indexing purposes. During indexing, each content item is divided into several chunks whose size is chosen to generate vector embeddings that accurately reflect its semantic meaning without overwhelming the LLM’s context window limit. For example, the open source vector database Milvus mentions a chunk size of 128-512 tokens - a token roughly corresponds to subwords of ~4 characters. But by subdividing the item, some chunks may miss the information that reflects the nature of the overall content item. The solution offered here is to repeat some fields in all the chunks - such fields are labeled as Contextual, whereas the Main content is the one being subdivided.
![]() A word of caution: This is probably the part that requires the most tweaking to get good search results!!
A word of caution: This is probably the part that requires the most tweaking to get good search results!!
Results
Once we’ve indexed the content in the index above, we’re ready to test the search:
/admin/config/ai/explorers/vector_db_generator
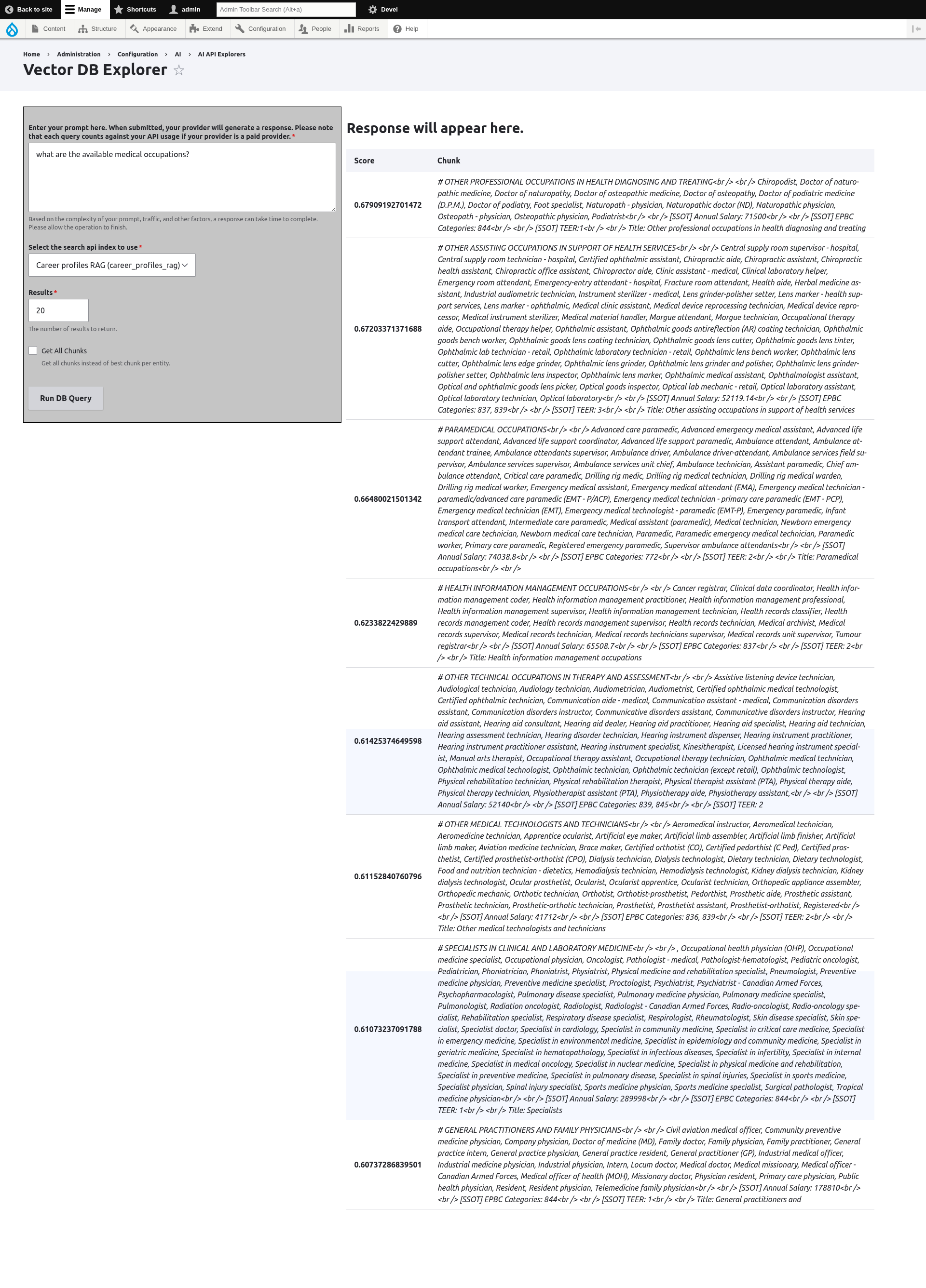
In case you’re curious, here’s the database table that the Search API server creates to store vector embeddings. You can notice that each node is broken up in several chunks, each starting with the node title which was selected as one of the Contextual fields above:
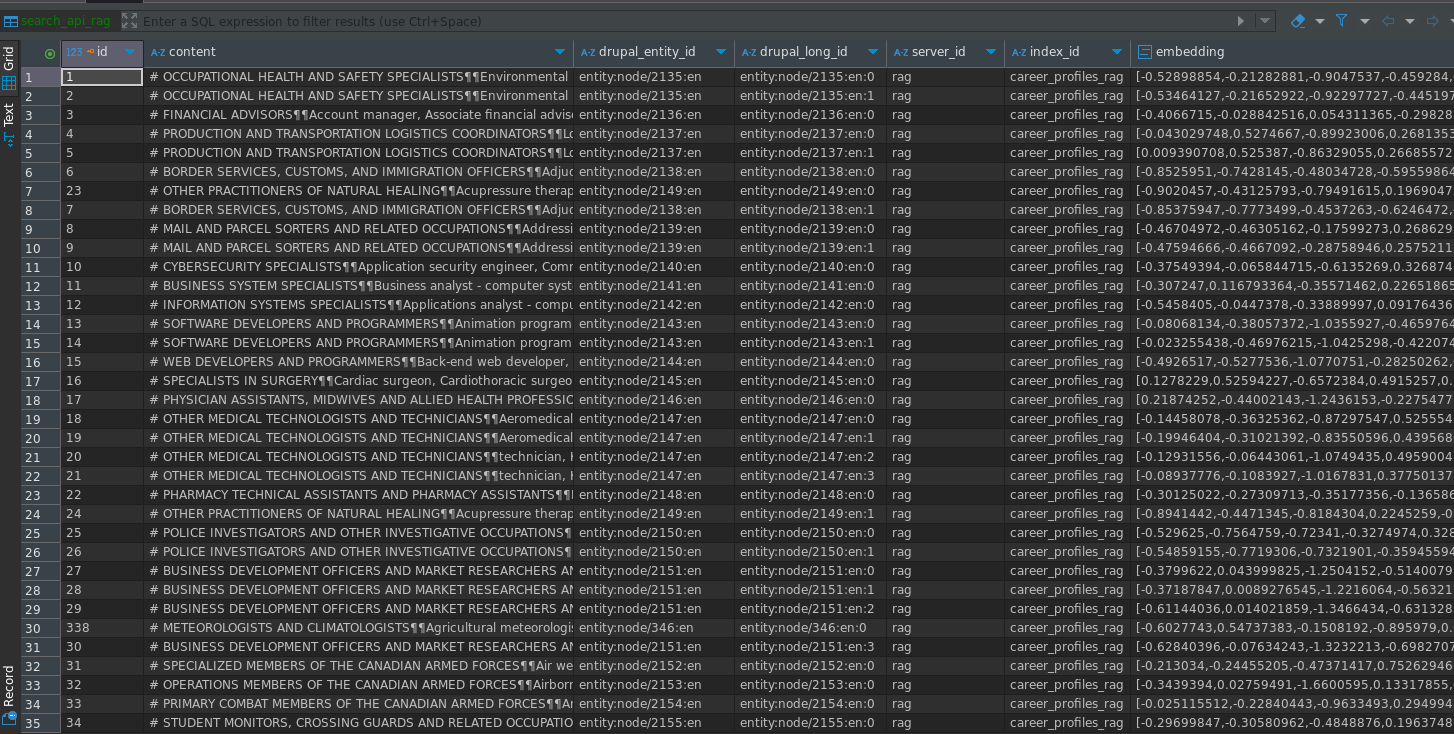
This concludes part 1 of my Drupal AI setup. Next time, I’ll look at more specialized Search API use case before getting into the treacherous waters of generated responses. Happy vibing ![]()
If you're looking for Drupal expertise, I offer Drupal consultancy services
 including:
including:
- Solution architecture
- Module development
- Service integration
- Content migration
- Troubleshooting and optimization
- Engineering leadership