A query tool for heterogeneous sheet music indexes
As a practicing musician, I often need to refer to sheet music when I learn a new tune. Oftentimes, I prefer to refer to multiple transcriptions of the same song in order to fine-tune my own interpretation of it. To help me locate the various transcriptions, I’ve created a small tool that takes a keyword and queries a meta-index, made up of various sheet music indexes I’ve found on the Web. The result is clumsily called Sheetdex.
Building the index
The Web has many sheet music indexes - some offered by the sheet music publishers themselves, others made by interested users like myself. Here are some of the indexes I’ve found:
- Jamey Aebersold has published an index of their play-alongs up to volume 133
- Hal Leonard has published an index of their real books
- Bob Keller has compiled a fakebook index as a Google spreadsheet
- Someone has compiled an index of Guitar Techniques articles as a Google spreadsheet
- Adam Spiers has compiled a CSV index of music books aimed at being incorporated into sheet music viewer apps
- Glenn Betcher had created another index of jazz standards that I could only find as PDF format (on Bob Keller’s page), so I converted it to a Google spreadsheet using an online PDF to XLS conversion service (and lots of subsequent manual fixing).
The idea of integrating these different data sources into a single index requires designing a schema that unifies the information supplied by each source, while allowing for inconsistent, missing and even conflicting data. I opted for a simple JSON nested book-tune model where the tune pages are explicitly stored as a named attribute, but other attributes (such as composer, tempo, tune key, etc.) are stored as “annotations” consisting of name-value pairs.
For each data source above, I created an ingestion routine that converts the source’s data format to the unified model above. Once all the data soures are ingested this way, I merge book and tune data from different indexes, by matching titles using a text normalization function. An interesting tidbit I found while merging object properties is that assigning undefined to a property causes the corresponding object key to disappear from the object. This turned out to be a handy way to reduce the code, allowing me to succintly express conditions where data may be missing:
sheet.page = existingSheet.page || sheet.page || undefined;
in which case sheet.page would be absent from sheet if neither existingSheet.page nor sheet.page are defined. Once the data is merged, the JSON index is cached to file and it is ready for querying.
Querying the index
To simplify querying, I’ve opted for a JSONPath implementation with a custom text matcher that normalizes text. This allows querying a single field in the JSON structure like sheet.title. The module I use allows to return a custom structure for each match, so I pluck the needed fields and return them to the caller in a JSON array.
There are problems with this approach:
- Each query traverses the full JSON index, because the fields are not individually indexed.
- To support more fields, like the author, I would need to add another JSONPath query and allow the caller to specify the field(s) to be queried.
I think I should migrate my index to a dedicated JSON database engine (like Elasticsearch) but I will leave this as the proverbial “future enhancement” ![]()
Exposing the command on the Web
To provide a UI for the tool, I’ve built a simple Express app that accepts a query argument, and serves the search form and the query results in a table. I’ve used the excellent ag-Grid to render the table, passing it the JSON query results from above verbatim. I love it when modules can just plug-in!
You can try the tool live. Here’s a screenshot:
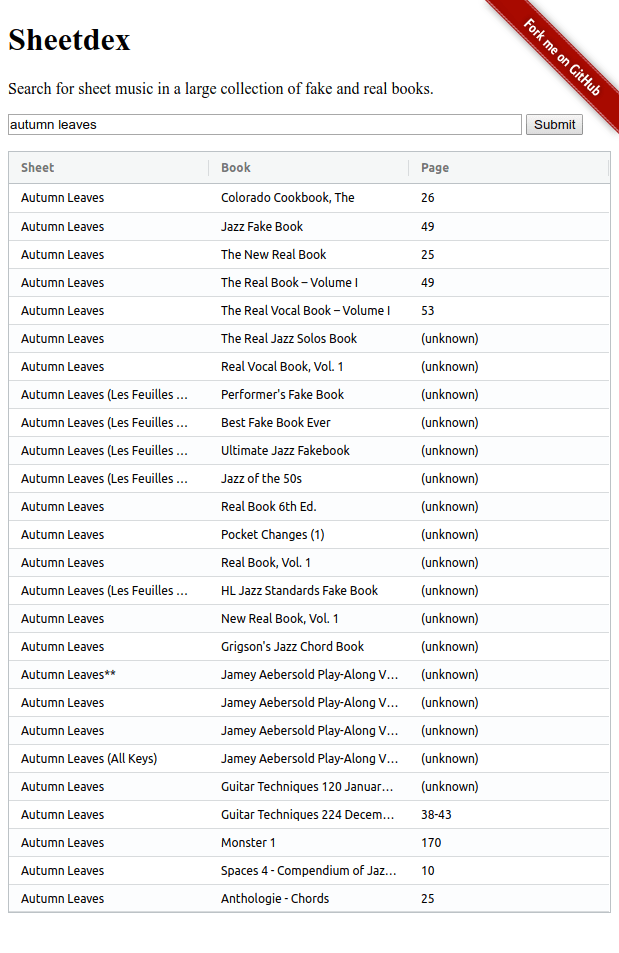
Now go play! ![]()
![]()